


Most SaaS companies are overstating their cost of goods sold. The entire cloud bill goes into COGS, gross margin takes the hit, and nobody questions it because there hasn't been a standard for how to do it differently. When cloud spend was one or two percent of revenue, that shortcut was harmless. At 10 to 20 percent of revenue, with AI costs compounding the problem, it is a material misstatement with real consequences for how the business is valued, funded, and operated.
That was the focus of a live session I hosted with Todd Gardner, Managing Director at SaaSonomics. Todd has reviewed over a thousand SaaS company financial statements across his career in venture and private credit, and he brought the investor and board perspective to a problem most finance teams are still navigating without a framework. Rather than talk about rising costs in the abstract, we got into the mechanics: what belongs in COGS, what belongs in OpEx, how to handle shared infrastructure, and how AI costs fit into all of it.
This session coincided with the public launch of two resources developed with input from dozens of CFOs and accountants.
Cloud Infrastructure Accounting Standards (CIAS) provide the governance framework for how cloud and AI infrastructure costs hit your P&L. CIAS interprets existing GAAP and IFRS principles as applied to cloud and AI infrastructure, covering classification, forecast variance controls, shared accountability, commitment disclosure, consistency, and capitalization.
Cloud and AI Infrastructure Costs: A CFO's Classification Handbook is the practical companion, walking through the classification framework, allocation methodology, AI cost treatment, commitment disclosure, capitalization, and a 30-day action plan.
If you'd like to run a classification exercise against your own cloud spend, Cloud Capital can map your costs automatically at no cost. Just book a call with us at cloudcapital.co.
Your cloud bill is not one cost. It contains hundreds of individual services running across multiple accounts, environments, and vendors. Development environments, staging clusters, internal security and compliance tooling, proof-of-concept infrastructure, cloud provider support packages: all of these commonly land in COGS despite having no direct relationship to customer delivery.
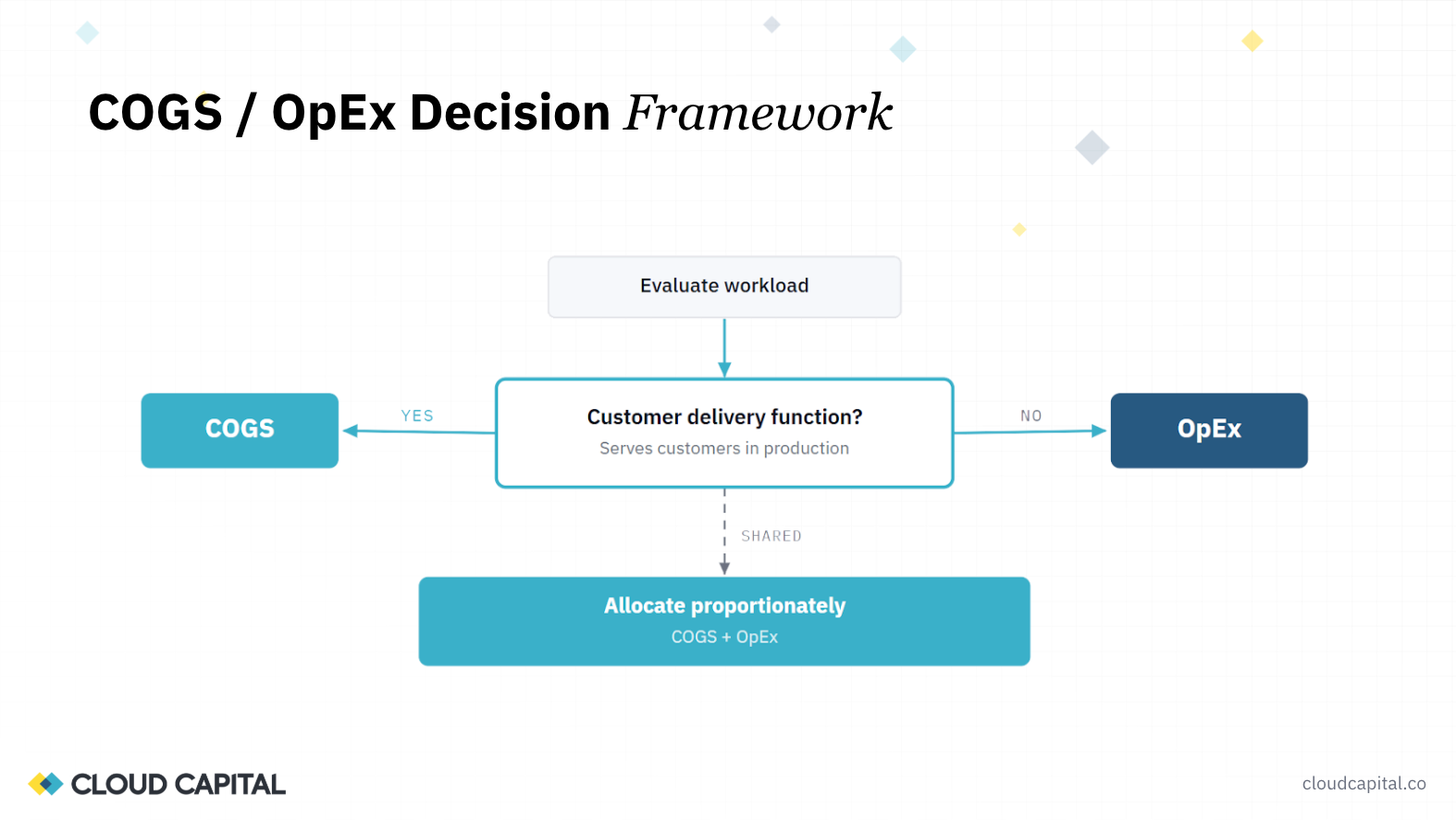
The governing question for any workload is simple: does it exist to deliver the product to customers? If it does, it's COGS. If it doesn't, it's OpEx. That distinction sounds basic, but applying it to a 70-page cloud invoice is where the difficulty lies, and where most finance teams default to the conservative (and margin-damaging) choice of putting everything in COGS.
Todd made the investor case for why this matters. COGS and operating expenses are treated very differently in valuation models. Forward-looking cash flow projections assume COGS scales with revenue, while operating expenses can be leveraged over time. Getting costs into the right category may not change your P&L today, but it changes your forward-looking P&L, which is what drives valuations. And as Todd pointed out, this conversation is going to happen in your first or second meeting with any investor: what's in your COGS, and where's the documentation?
He also raised an important default to keep in mind: if a cost has not been specifically allocated and documented, investors will assume it is COGS. The burden is on the finance team to credibly demonstrate otherwise.
We walked through a two-step approach that any finance team can apply immediately.
The first step is account-level segmentation. Cloud providers organize infrastructure into accounts (AWS) or projects (Google Cloud), and engineering teams typically name them in ways that signal function. Anything labeled "production" or "prod" is a strong indicator of customer-facing infrastructure. Anything labeled staging, development, sandbox, or testing is a strong indicator of OpEx. The naming conventions are imperfect, but they provide a fast first pass across the majority of your spend.
The second step is service-level analysis. Within those accounts, individual cloud services carry classification signals of their own. Compute, databases, and storage in a production account are almost certainly COGS. Security tooling deployed for SOC 2 or ISO compliance, monitoring infrastructure, and technical support packages from the cloud provider are almost certainly OpEx. Support costs alone can run at 10 percent of the total bill and scale linearly with the rest of your spend.
Together, those two dimensions handle the bulk of the classification work. For the remainder (shared workloads that serve both production and non-production functions), the session and our published handbook cover allocation methodology in detail, including how to select a driver, document the split, and determine review cadence.
AI is making this problem harder and more urgent simultaneously. We broke AI costs into three categories, each with a distinct classification treatment.
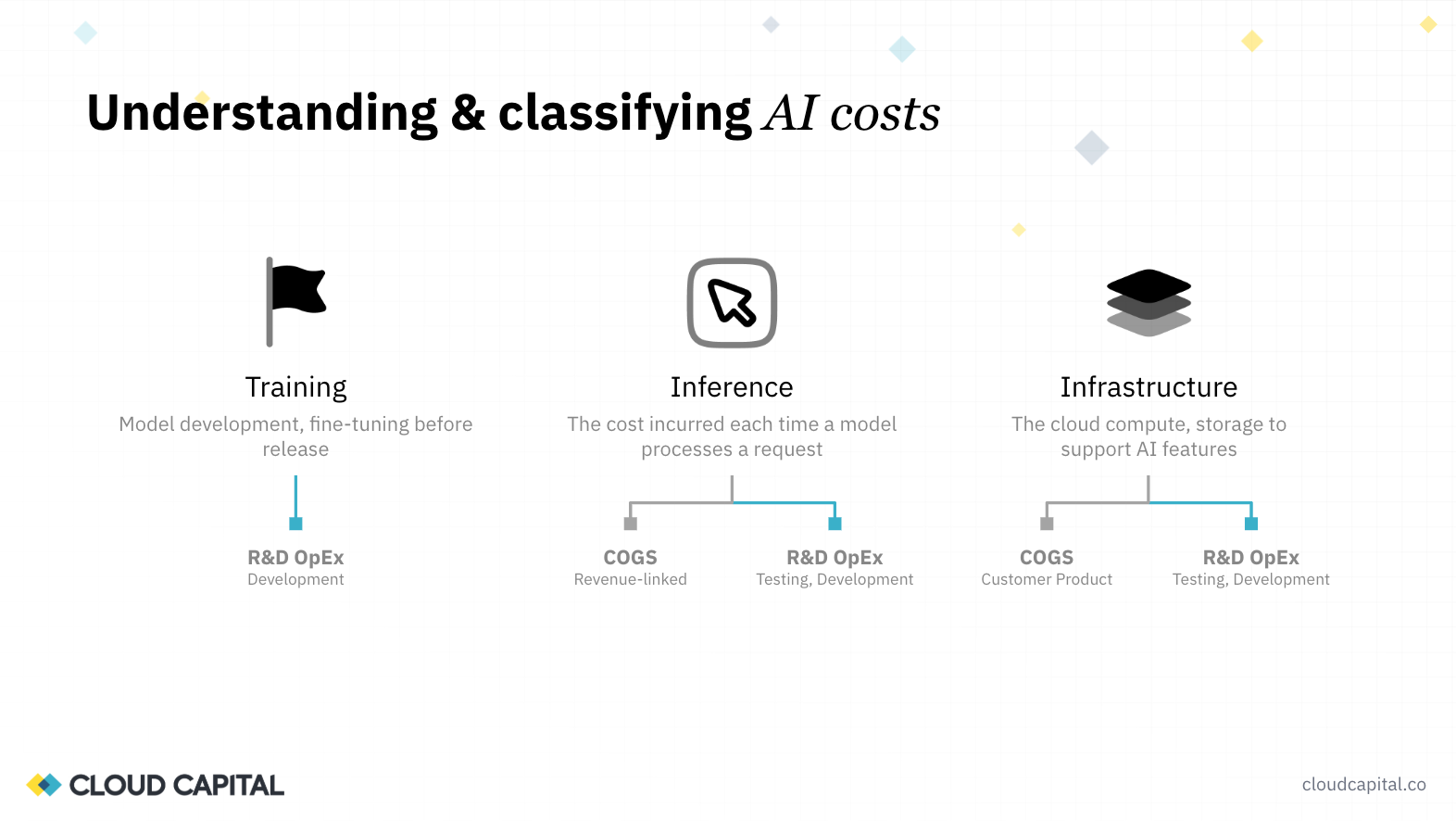
Training and fine-tuning (developing or iterating on your own model) is R&D OpEx. This is a capital investment in a new capability, and including GPU training costs in your gross margin can dramatically misrepresent the economics of the business.
Customer-facing inference (the cost incurred each time a model processes a request as part of your product) is COGS. These costs are driven by customers using your product and belong in gross margin.
Supporting infrastructure (the incremental compute, data processing, and storage required to run AI workloads) follows the same classification logic as traditional cloud spend: production workloads in COGS, everything else in OpEx.
The practical guidance is to isolate these cost streams early. If your engineering team is testing an Anthropic or OpenAI model, have them run that work in a separate account. If you're training your own model, separate those GPU costs completely from production inference. The token costs your engineering team incurs during development should not appear in your gross margin.
We walked through an illustrative example that reflects what we see regularly. A $20M ARR company spending $4M on cloud (20% of revenue) that books the entire bill to COGS shows a 65% gross margin. Through classification, if 20% of that cloud spend is identified as non-production, the margin moves to 69%. Four points recovered, same spend, same business.
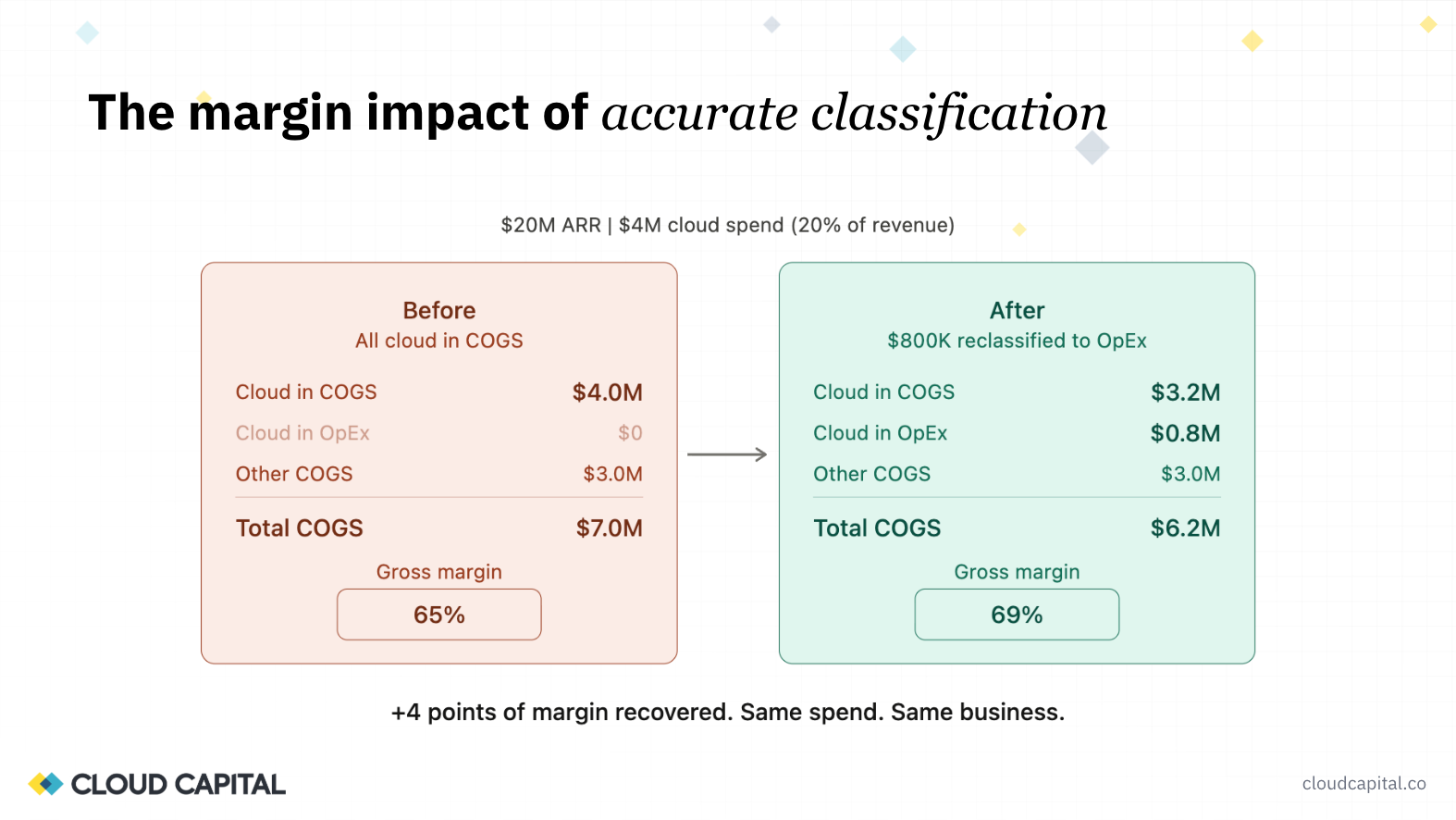
As Todd was careful to clarify: this is not an improvement in gross margin. It is a more accurate reflection of gross margin. That distinction matters when presenting the change to investors or your board. There are operational ways to improve margin (optimizing infrastructure, negotiating commitments, reducing waste), and those are separate conversations. Classification is about making sure the starting number is right.
One of the clearest findings from the Cost of Compute 2026 data is that every metric around cloud cost visibility, predictability, and forecast accuracy improves when finance and engineering own the process together. Companies that forecast cloud costs monthly with driver-level visibility (which requires engineering input on tagging and workload attribution) achieve roughly three times the forecast accuracy of companies using baseline methods.
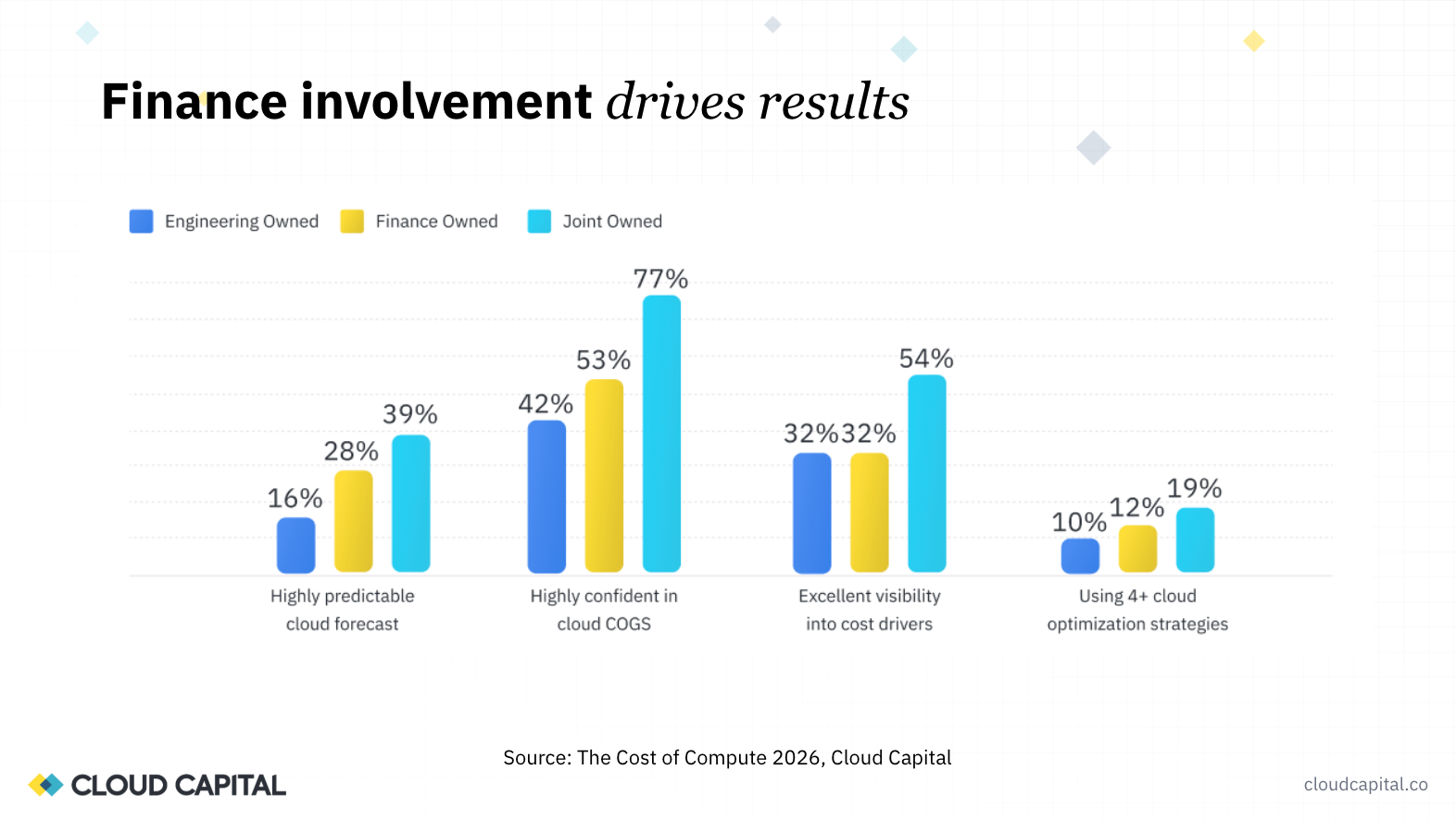
Neither team can solve this independently. Finance owns classification policy and reporting. Engineering owns resource consumption, tagging, and the context required to understand what each workload actually does. The teams getting the best results are those that built a shared vocabulary and a regular review cadence early.
Full transcript from the webinar "The CFO's Cloud Problem: AI Costs, Margin Risk, and the Governance Gap," hosted by Ed Barrow (Cloud Capital) and Todd Gardner (SaaSonomics). Edited for brevity and clarity.
Ed Barrow: Welcome everyone. Today's session is focused on one of the most critical foundational areas for CFOs right now: how do you accurately report on your cloud and AI costs? These are line items that are growing rapidly and unpredictably, and making sure they're aligned correctly on your P&L and in your financial model is incredibly important when you're thinking about how the economics of your business work and how you're going to scale successfully.
I'm Ed Barrow, Founding CEO of Cloud Capital. We provide the financial control layer for AI and cloud infrastructure, built for CFOs. I'm also very excited to be joined by Todd Gardner. Todd, would you like to introduce yourself?
Todd Gardner: Thanks, Ed. Happy to be here. Today I'll primarily be playing the role of investor and board member. I was in venture for 10 years. I started and ran a company called SaaS Capital, which also invested in SaaS companies. And honest to God, I've looked at over a thousand SaaS company financial statements.
Ed: Lucky you.
Todd: My kids are really excited when I say that fact. But being exposed to this emerging problem from quite a few different angles, I'll bring that perspective today.
Ed: Let's set the scene. At the end of last year, we surveyed over 100 growth-stage SaaS CFOs to understand where they are on this journey. The results were very clear and quite challenging.
Software companies are now spending somewhere between 10 and 20% of revenue on cloud infrastructure. That is a really meaningful number, up materially from the last few years. For many technology companies, it's their second-largest line item after headcount, and yet it's far less well understood, far more volatile, and far less predictable. And we're witnessing the rapid rise of AI costs as part of this, which is making the problem worse, faster.
Todd: You're not alone. Ninety percent of CFOs in that survey reported downward pressure on gross margins, driven by AI. Although in some previous research I've done, even if you're not doing AI yourself, AI is putting so much cost pressure on the cloud that it's driving everybody's costs up. AI in particular is challenging because it's new and it's less predictable.
Ed: Gross margin has become the number one topic people are talking about. I think actually today, more than growth. Growth has obviously been the key metric that's driven a lot of the technology industry, but gross margin has risen to be a critical topic far earlier for many organizations in their evolution than it once was.
The core challenge we're going to focus on today is classification. Perhaps the most important thing to understand is that not all of your cloud spend, nor all of your AI spend, should actually be part of your cost of goods sold. When we put that entire AWS or Google Cloud bill into our gross margin, we are potentially having a very damaging impact on how we're presenting our businesses. When that was 1 or 2% of revenue, it wasn't necessarily a big problem. At 10 to 20% and growing, getting this right is critically important. There are cascading impacts on pricing, on sales and marketing investments, on what you can ultimately do to scale.
Ed: Todd, from an investor lens, how do you think about getting that margin right?
Todd: It's funny, some people say it doesn't matter where it is on the P&L, it's the same cost and the same net income at the end of the day. That's just not true. Venture, PE, and acquirers all treat COGS very differently than they treat operating expenses. That's primarily because valuations are driven by forward-looking cash flow streams.
COGS scale differently than operating expenses. When people are doing pro formas and discounted cash flow models, they're not going to mess with your gross margin much. But operating expenses do tend to scale over time, and those drive future profitability as you scale, unlike COGS. So getting costs in the right buckets may not change your P&L today, but it definitely changes your forward-looking P&L, which is what drives valuations.
Last thing I'll say: at SaaS Capital, we lent money based, to some degree, on gross margins. We would lend more money to a customer with higher gross margins per dollar of revenue, because they have a bigger growth engine and the capacity to generate more cash. We were more aggressive about investing in those companies.
Ed: Absolutely. There's the operational side of getting your gross margin right for internal investment decisions, but every fundraising conversation we're supporting right now is much more focused on gross margin and where it's going to end up. How much cash can this business generate from every dollar of revenue is a fundamental input into those conversations.
Todd: The other thing I'd say as a framing thought: unlike growth, which there's really only one way to measure, that's not true with COGS and gross margins. This is a conversation that's going to happen in your first or second meeting with an investor. What's in your COGS? How do you support it? Where's the documentation? There can be differences of opinion, but it still needs to be rationally thought through. Gross margin is still the Wild West to some degree.
Ed: Absolutely. And particularly when it comes to cloud and AI spend. This is the area we've seen be one of the most challenging, and why we're here today.
We've spent a lot of time with dozens of CFOs in the last few months on this very challenge around correctly classifying cloud and infrastructure costs. We've compiled that work into two guides. First, we've just launched today our CFO's Classification Handbook for cloud and AI cost classification, which provides a clear, step-by-step guide to understanding how to separate and correctly classify these costs on your P&L. That's backed by our new Cloud Infrastructure Accounting Standards, which provide the solid foundation for that work, grounded in existing GAAP and IFRS standards.
Today we'll focus on giving you practical, tangible guidance on how to think about cloud spend and a clear action plan. The guides also cover capitalization, commitments, and other important areas, but classification is where we'll spend most of our time.
Todd: I'll start at a high level. The core fundamental question, which you can apply to any cost, is: does this workload support a customer delivery function? I think about it a couple of ways. If we stopped paying for this, would we have churn? Do paying customers rely on this functionality, support, or workload? "Paying" is an important word in that phrase.
If they do, that's directly related to cost of goods sold. If not, it's primarily a resource used internally, and that's OpEx. On occasion there will be shared resources, and we'll talk about how to allocate those.
Ed: This is the crux of it. It's a fairly standard question for any COGS-related item: does it support customer delivery? The challenge with cloud spend is that it's not one thing. Your monthly bill is typically an indecipherable 70-page PDF with a lot of different individual cloud services. Being able to answer that question for each component is really where the difficulty lies.
Ed: Where does the rubber hit the road? There's actually a pretty simple two-step process.
Most cloud providers have two major constructs to think about. The first is accounts. Within your AWS system, your engineering team will have created multiple accounts: umbrella structures in which they operate different parts of their infrastructure. On Google Cloud, these are called projects instead, just to confuse everyone.
What you're looking for in the account names is terminology that signals function. "Production" or "prod" is what engineering teams use to describe customer-oriented infrastructure. That's a strong indicator that it's likely used for customer delivery. Conversely, if the account is called staging, testing, development, or sandbox, that indicates it's infrastructure being used by your engineering team to build software. That's OpEx.
Engineering teams often do a reasonable job of separating at a high level. The unfortunate thing is that policy isn't always strictly enforced, and there's often one big account used to run multiple things. A classic scenario is the account named after the founder. When you set up your cloud infrastructure for the first time, they ask if you want to name your account, and a lot of CTOs and founders stick their name in. So you'll have something like "Joe Bloggs" as the big catch-all account, and then more conventional naming elsewhere. But it's a really practical starting point.
The second level down is services. Cloud is not one product. It's often hundreds of different individual services covering compute, databases, file storage, networking, security, monitoring, and support. Certain services in a production account are highly likely to be part of customer delivery: compute, databases, storage. Conversely, security tooling, monitoring, and technical support are services that may be running across different accounts for internal purposes. Internal monitoring, security and compliance tooling for SOC 2 or ISO certifications, support packages that help your engineering team operate infrastructure: these are what you want to identify and pull into OpEx.
Todd: I like thinking about the word "direct." It's directly supporting your customers. You can get twisted around saying, well, I need security to support the whole thing. But it's really a tighter definition than that in terms of what goes into COGS.
Todd: Some things aren't easily split or aren't split by your cloud provider. Take a data warehouse as an example. I'm sure everybody on this webinar has done allocations before. What I'd like to reinforce is: one, documentation. Write down what your key driver is. For a data warehouse, a likely driver is number of queries. Then you're going to need to pull the data and figure out how much was really associated with customers versus your internal dev team.
As you do that analysis, think about two things. First, how big is this line item? If it's relatively small, do the analysis once a year. It's just not going to drive a meaningful difference in your P&L. Second, look at how much it changes month to month. If it's a meaningful line item and it's bouncing around, you'll need to tackle it monthly, which means probably finding a way to automate that.
The thing you really want to avoid is changing the drivers. I've looked at financial statements where they're changing allocation methodologies on a regular basis, and it's indecipherable. You cannot do trend analysis on those businesses. The most important thing when you start an allocation is to make sure you've got the driver right, and then don't shift it around.
Ed: Absolutely. It's about spending time with the engineering team to identify the sensible, reliable driver. Database queries or data storage volumes are great examples. And this is only a relatively small proportion of infrastructure that's genuinely shared between production and non-production environments. It's not an area that's going to dominate.
Todd: I think we missed a point earlier. If you don't allocate it, it stays in COGS. If I'm an investor and I'm looking at it and it's in your AWS bill and you haven't addressed it in some specific way, I'm going to assume that's COGS. You can't just say, "I'm sure we use it in dev," and move it to R&D.
Ed: That's really important. The default should be: if in doubt, this is COGS. What we're doing is a process of extracting out of that bill what we can sensibly and credibly place into OpEx. That's the right motivation.
Ed: Let's step back and say, why do this at all? What is the actual impact?
Here's an illustrative example grounded in what we see very often. A $20 million revenue business spending $4 million on cloud, that's 20% of revenue, which is not uncommon today. If the default assumption is to put that entire AWS bill as a single line item into COGS, you're looking at a 65% gross margin. Frankly, a lot of companies would be happy with 65% right now.
But through this classification exercise, if we can identify just 20% of that bill as testing, development, and staging costs and pull that into OpEx, we've moved the gross margin from 65% to 69%. That's a four-point swing purely through classification, and it can be incredibly meaningful.
Todd: Keep in mind: you're not technically improving your gross margin. You're better reflecting your gross margin. When talking with investors, you need to be careful about that. There are operational ways to improve your gross margin, and then there's getting it properly classified. You don't want to present it as a trend.
But it's absolutely real. This will undeniably improve the business's valuation, because some of those four points are going to make their way to the bottom line as the business scales. The assumption will be that the business throws off more cash flow in the future with a higher gross margin, even if it's offset dollar for dollar today by operating spend.
Ed: Let me walk through four common examples where we see classification challenges.
The first and most obvious is development, sandbox, and staging environments. This is the single largest source of overstated COGS. Start with the account name. It's actually really easy to find, and it's a great starting point for pulling costs into OpEx.
The second is security and observability. Monitoring and security costs may be tied directly to your production environments, but a lot of it is internal tooling. If you're going through SOC 2 or ISO compliance, you have to layer on additional security services. Being able to identify those and say, "We deployed these for our SOC 2 certification, that's an internal compliance tool," and pull that into OpEx.
The third, which is really interesting, is proof-of-concept and demo environments. We get this question a lot, particularly from organizations in cybersecurity and data analytics that run compute-intensive POCs to demonstrate value. The key point is that this isn't serving your production customers at scale. The test is: if you didn't run those POCs, you might not win business, but you're not churning business either. These should often be considered as part of sales and marketing.
Todd: I've seen that one in a number of cases, usually in early-stage businesses. It can be quite meaningful.
Ed: The last one is support services. I'll make a clear distinction here: this is not the support you're charging to your customers. This is the support cost you're paying to your cloud provider. That's fundamentally about providing advisory services to your engineering team so they know how to build and scale a platform. Unless you're reselling that support to customers, which is very rare, it should be in OpEx. And often this can be 10% of the bill. Enterprise support plans are typically priced as a percentage of your total cloud spend, so it scales linearly and can be quite meaningful.
If you're able to take your development and staging costs out, pull support costs through, and separate your POC spend, you're already making really meaningful progress on getting the classification right.
Ed: Todd, you had an interesting point on capitalization.
Todd: I'll go quickly on this. Some SaaS companies have a fair amount of upfront cost in their deployments. In this particular case it was data ingestion: they needed to load a lot of data before they could get a customer up and running. They were showing negative gross margins on those customers. They were also a small company that was layering on new customers rapidly, so almost all their customers were in that early stage. While they had a highly profitable long-term customer in terms of unit economics, they were showing negative gross margins and couldn't even start a conversation with an investor.
I'm generally not a fan of capitalizing any expenses because it divorces the P&L from cash, which can be dangerous. But in this case, it really improved transparency and visibility about the long-term prospects of the business. It was a better way to communicate the real economics, as long as you educate your board and investors around the cash implications, because you're still burning the cash even if you're capitalizing the cost. Something to think about for companies with a decent amount of upfront one-time cost as they ramp customers.
Ed: Certain sectors within SaaS have far more exposure to this, particularly if you're doing upfront data processing. I've actually seen the opposite: a data analytics company where they continuously store more data for the customer. In the first few months, they're not storing or processing much, but they keep amassing more data without thinking about retention. That interacts with your growth rate. If you're seeing negative gross margin early in the customer lifecycle, the faster you grow, the worse your margin looks because a larger proportion of customers are in that early stage. It's a really interesting intersection between growth and margin.
Ed: If you've gotten this far and feel confident about tackling your core AWS, Google, or Azure bill, unfortunately your life may not have gotten easier just yet. AI costs have arrived on the scene. These are a whole new set of services growing very rapidly.
Going back to our survey, AI costs are growing incredibly quickly for many software companies and are now major contributors to gross margin degradation. We're seeing organizations that maybe spend $200,000 or $300,000 a month on traditional compute, and then suddenly in the last three or four months their AI bill has gone from a few thousand dollars to tens of thousands to now hundreds of thousands of dollars a month. These costs are less predictable and harder to classify.
There's also a whole new language. I always ask the question: does everyone know what a token is? It's often not the easiest thing to understand, and the way these costs scale and operate is very different from traditional compute.
When we think about AI spend, there are three distinct categories. First, training: if you're developing and training your own model, you're incurring material costs for running GPUs, training, and fine-tuning. The big headlines about what OpenAI and Anthropic have spent on training are front-page news, but many organizations have tackled this individually as well.
Second, inference: a lot of companies have decided it doesn't make economic sense to train their own model and instead use an existing model from OpenAI or Anthropic, embedding that within their product. Inference is about taking an existing trained model and using it within your infrastructure, and it scales as the model is used.
Third, underlying infrastructure. If you're running AI, you're going to incur more core compute costs associated with data. You need to gather data from your users, pass it to the model with a prompt, get the information back, process it, and present results. As your AI and inference costs grow, so do your associated infrastructure costs.
The classification is straightforward. If you're training and developing your own models, that is R&D OpEx, not COGS. That is fundamentally developing your intellectual property. Make sure you can isolate those costs: run them in a separate account, separate project, or separate billing.
For inference, it's similar to regular compute. You may be using Anthropic or OpenAI models embedded in your product, and that's part of customer delivery. But your engineering team will have used tokens to test and develop that technology. Making sure that testing happens in a development or staging account, so you can split those costs out and keep engineering token usage out of your production costs.
For infrastructure, apply exactly the same principles we've been talking about for core compute to all the incremental infrastructure costs from AI usage.
The practical advice: if you're testing a new model, run it in a separate account. If you're training your own model, isolate that completely. Simple processes and rules that make it easy to know what those costs are.
Todd: This is more data from the survey, and it's pretty obvious based on what Ed just went through: it's a team effort. Everything improves when finance and engineering work together. Each of these groupings is a metric around visibility to COGS and predictability, and in each case companies perform better when it's a jointly owned activity. Finance might notice that they outperform engineering in every case, but nobody's as good as the joint effort. It really requires an ongoing discussion, both in categorization and in ongoing forecasting.
Along similar lines, these are activities done with engineering that improve forecast accuracy. If you forecast monthly, it improves over baseline by about 1.4x, roughly 40% more accurate. Not a big surprise. But if you get down to driver-level visibility, which you can only do in conjunction with engineering through tagging and understanding cost drivers, you get a 3x improvement in your ability to forecast.
And then putting actual guardrails around spend, hard caps or approvals, not only constrains your spend but makes you more focused when you develop the forecast, knowing you might need to ask for approval if you go over. These data points support these activities as best practices, in addition to getting the categorization accurate.
Ed: If we think about a practical plan, all of the action plan detail is available in the handbook, so you have a clear guide for what to do. But we've traced through the core steps already. Take your cloud bill and segment it between production accounts and testing, development, and staging accounts. Dig into the service level to isolate support costs and security and compliance costs. Where you have shared workloads, engage closely with engineering to understand how those shared services are being used and what the right allocation drivers are. Establish a monthly review cadence.
This infrastructure is going to evolve. Your engineering team will start using new products and services, particularly with AI, and those can scale very rapidly. How you did your classification 12 months ago may need to evolve. But ultimately there's a really clear payoff. As we said at the beginning, you're not improving the margin itself, you're more accurately reflecting the reality of what your true gross margin is. That underpins everything important about the core economics of your business: the forecasting that your board and investors can trust, and the ability to demonstrate that AI spend is governed and delivering real value. That's a topic at almost every board meeting right now.
This may have given you a lot of useful information and also a daunting task list. One of the things we do here at Cloud Capital is automate a lot of this mapping. Our platform can analyze your current cloud spend, the services, accounts, and underlying workloads, and apply the standards and policies we've discussed to classify your costs. You can get a clear automated allocation in a matter of minutes and start to make meaningful progress. If you're interested, reach out and we can run that process for you. There may be a material improvement in your gross margin classification that can help in your next board meeting or fundraising process.
Todd, anything you wanted to add?
Todd: Nope, that's good. Thanks for having me. Appreciate it.
Ed: Thanks very much, and thanks everyone for joining us today.


Data directly from 100 CFOs
15+ charts & data visualizations
Together with operators guild



